



Unlocking LLM Potential with Retrieval Augmented Generation
RAG is a method that significantly enhances the capabilities of LLMs. RAG functions as a prompt engineering technique, enriching the output of LLMs by integrating an information retrieval component into your systems of record and data sources like CRM, HR, and external knowledge bases. Doing so provides AI systems with timely, accurate, and domain-specific data – a marked improvement over conventional large language models that often operate with static or outdated training data. This improves the LLM’s ability to generate accurate responses and limit hallucinations.
The Mechanics Behind RAG
Retrieval
The power of RAG lies in its novel approach to data gathering and handling. At its heart, RAG boosts AI responses by retrieving up-to-date information and data in real-time from your systems of record or from a knowledge library, depending on your use case. To retrieve relevant information ensures that AI models operate with your domain-specific data, allowing them to answer questions and generate responses that are highly relevant based on the context of the conversation.
Augmentation
 The augmentation process in RAG capitalizes on real-time data retrieval from integrated systems and knowledge bases to generate and augmented prompt. This integration helps construct more detailed and accurate prompts therefore improving the accuracy of responses to a user’s query. Why is this significant? Well, in a world driven by data, the accuracy and relevance of information can be the distinguishing factor between a valuable, actionable insight and a futile one. Imagine prompting models for such knowledge-intensive tasks like customer service with numerical representations of customer records and payment histories in an efficient manner. This removes the need to train users on prompt engineering to answer difficult customer queries. When AI models can access real-time data, natural language processing delivers more accurate and contextual responses based on each conversation. This makes RAG a revolutionary method, ensuring your AI produces not just smart but context-smart responses.
The augmentation process in RAG capitalizes on real-time data retrieval from integrated systems and knowledge bases to generate and augmented prompt. This integration helps construct more detailed and accurate prompts therefore improving the accuracy of responses to a user’s query. Why is this significant? Well, in a world driven by data, the accuracy and relevance of information can be the distinguishing factor between a valuable, actionable insight and a futile one. Imagine prompting models for such knowledge-intensive tasks like customer service with numerical representations of customer records and payment histories in an efficient manner. This removes the need to train users on prompt engineering to answer difficult customer queries. When AI models can access real-time data, natural language processing delivers more accurate and contextual responses based on each conversation. This makes RAG a revolutionary method, ensuring your AI produces not just smart but context-smart responses.
Generation
The generation phase in RAG is often misconstrued as the primary aspect of the solution, whereas in reality, it constitutes merely 5% of the entire process. The actual magic happens within the retrieval and augmentation stages. LLMs often face a deficiency in domain-specific information, which RAG rectifies by incorporating context and domain-relevant data while generating content. Thus, RAG plays a critical role in how effective LLMs can be. This is undeniably the most critical part of the solution. But why so? This real-time data retrieval and integration drastically mitigates the risk of “hallucinations” or inaccuracies in the AI’s responses. By grounding the generated answers in fresh and relevant data, RAG substantially improves the precision and reliability of AI outputs. It’s not just about generating an answer; it’s about generating the right, contextually accurate answer based on the internal information of each conversation and interaction.
How do you Implement Retrieval Augmented Generation?
Implementing RAG involves a series of steps that integrate and utilize both structured and unstructured data. The process can be broken down into several key stages:
1. Identifying and Gathering Unstructured Data
The first step involves identifying all the relevant unstructured data within an organization. This data typically includes documents like call scripts, standard operating procedures, FAQs on product usage, and any other relevant documents. The challenge here lies in efficiently indexing and searching through this vast array of unstructured data.
2. Using Vector Databases for Unstructured Data
Once the unstructured data is gathered, the next step is to make it searchable. This is achieved by using software to perform embeddings on the data, transforming it into a format that can be indexed and searched within a vector database. The use of a vector database is crucial as it allows for the efficient handling of large volumes of unstructured data.
3. Integrating APIs for Structured Data
 In addition to unstructured data, structured data is also vital for a comprehensive RAG system. This data typically comes from APIs and includes real-time, structured information like order dates, numbers, customer IDs, customer emails, and other specific data fields. The structured nature of this data means there is no ambiguity in the data fields, making it a crucial component of the RAG system.
In addition to unstructured data, structured data is also vital for a comprehensive RAG system. This data typically comes from APIs and includes real-time, structured information like order dates, numbers, customer IDs, customer emails, and other specific data fields. The structured nature of this data means there is no ambiguity in the data fields, making it a crucial component of the RAG system.
4. Combining Unstructured and Structured Data
The core of RAG lies in the ability to use both unstructured and structured data in tandem. When responding to a query or generating content, the system should be able to retrieve and utilize information from both data types. This combined approach ensures a more accurate and contextually relevant response.
5. Addressing Complications with Unstructured Data
Implementing RAG is not without its challenges, especially when dealing with unstructured data. Issues such as data sourcing from external sources, ensuring the data’s current relevance, and maintaining security are all critical. For example, company policies may change over time, so the system needs to discern which policy is appropriate for the current context. Security is another major concern, particularly with sensitive data like emails and customer information, which may require role-based access control.
6. Security and Efficacy
Ensuring security and efficacy around unstructured data is paramount. While APIs typically have inherent security measures, unstructured data requires additional attention. This includes securing the data, ensuring only authorized personnel have access, and maintaining the data’s relevance and accuracy.
Real-World RAG Example: Customer Service Excellence
Picture this scenario – a customer is eager to purchase a new product. Just as they prepare to finalize the order, a message pops up – “Your order is on hold. Please contact customer service.” Naturally, they reach out to customer service, detailing the issue at hand – an order that is inexplicably on hold.
The service agent, seeking to resolve the issue promptly, turns to their AI assistant, Krista, and asks, “Why would customer orders go on hold?” Here is where RAG comes into play.
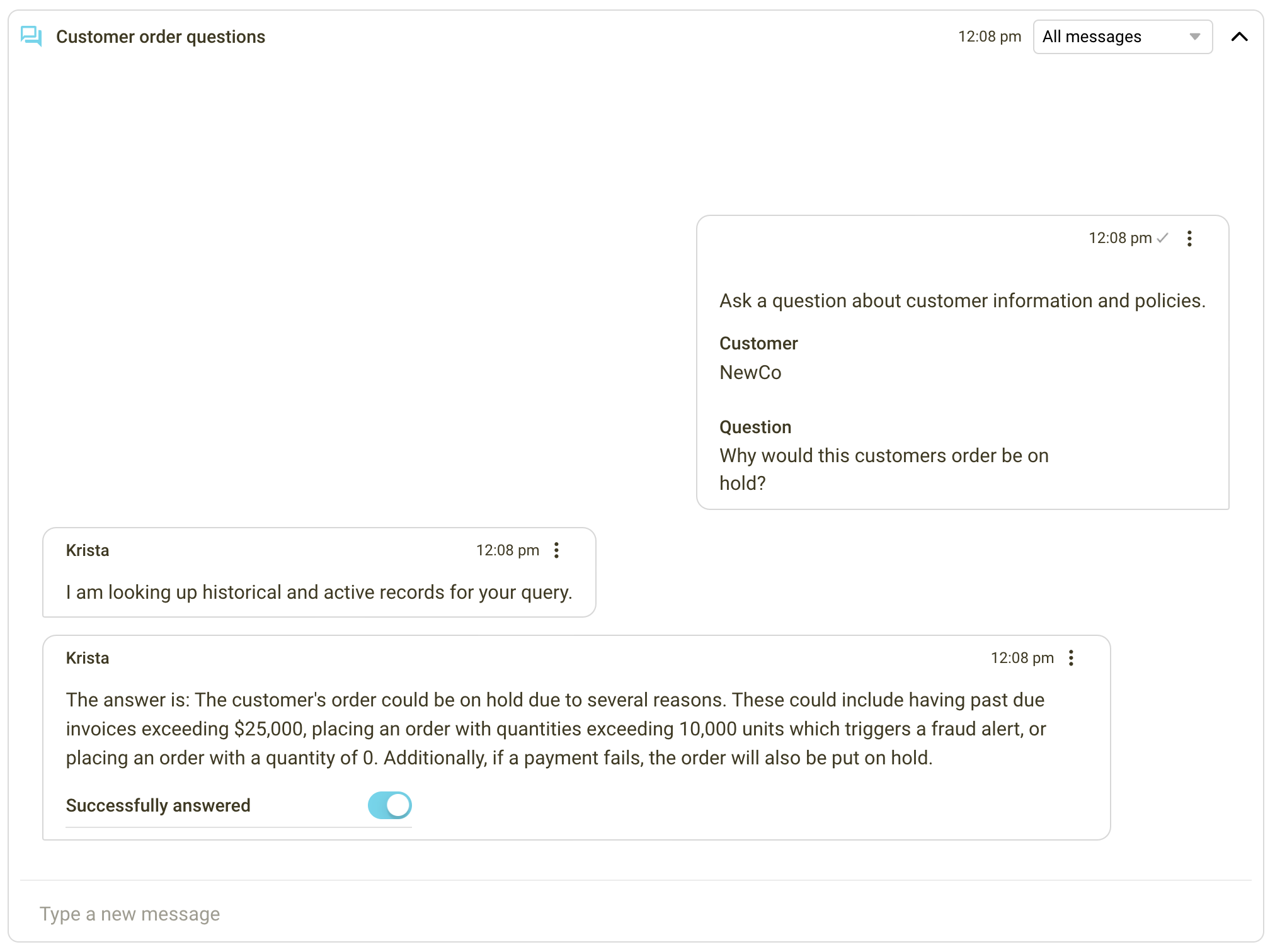
Krista leverages RAG to retrieve information from several data sources like FAQ and knowledge base articles, offering an answer that mirrors the company’s policies. Krista states, “Customer orders could be on hold due to past due invoices exceeding $25,000, orders with quantities surpassing 10,000 units (triggering a fraud alert), orders with a quantity of 0, or payment failures.”
Let’s go a step further. The agent, aiming to determine if overdue invoices are causing the hold, inquires, “Does this customer have past due invoices totaling over $25,000?“
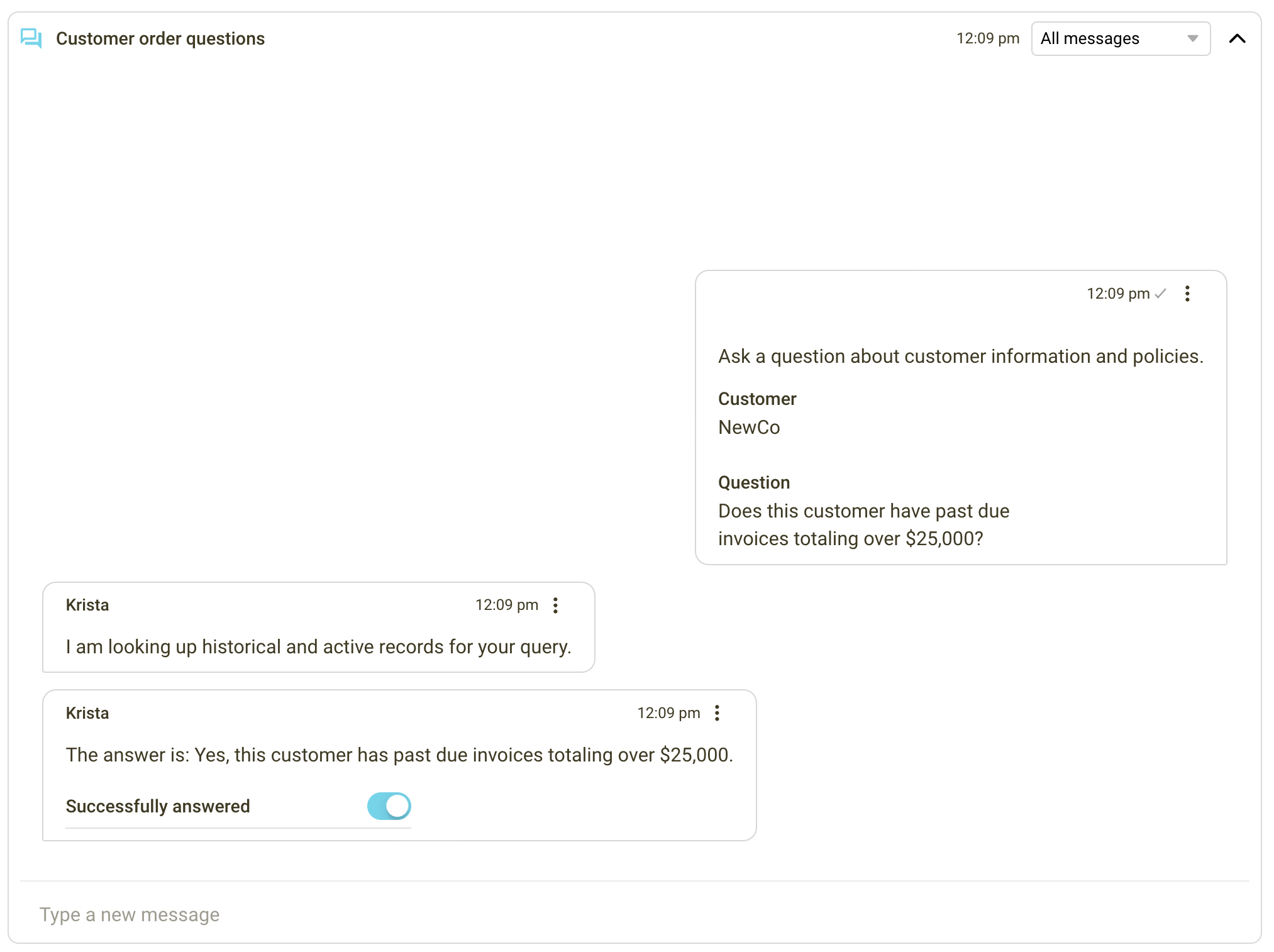
Krista retrieves necessary customer data from the CRM and payment systems, scrutinizes the invoices, and delivers a precise, timely response: “Yes, this customer has past due invoices totaling over $25,000.”
But what about specifics? The agent asks, “What invoices are past due?“
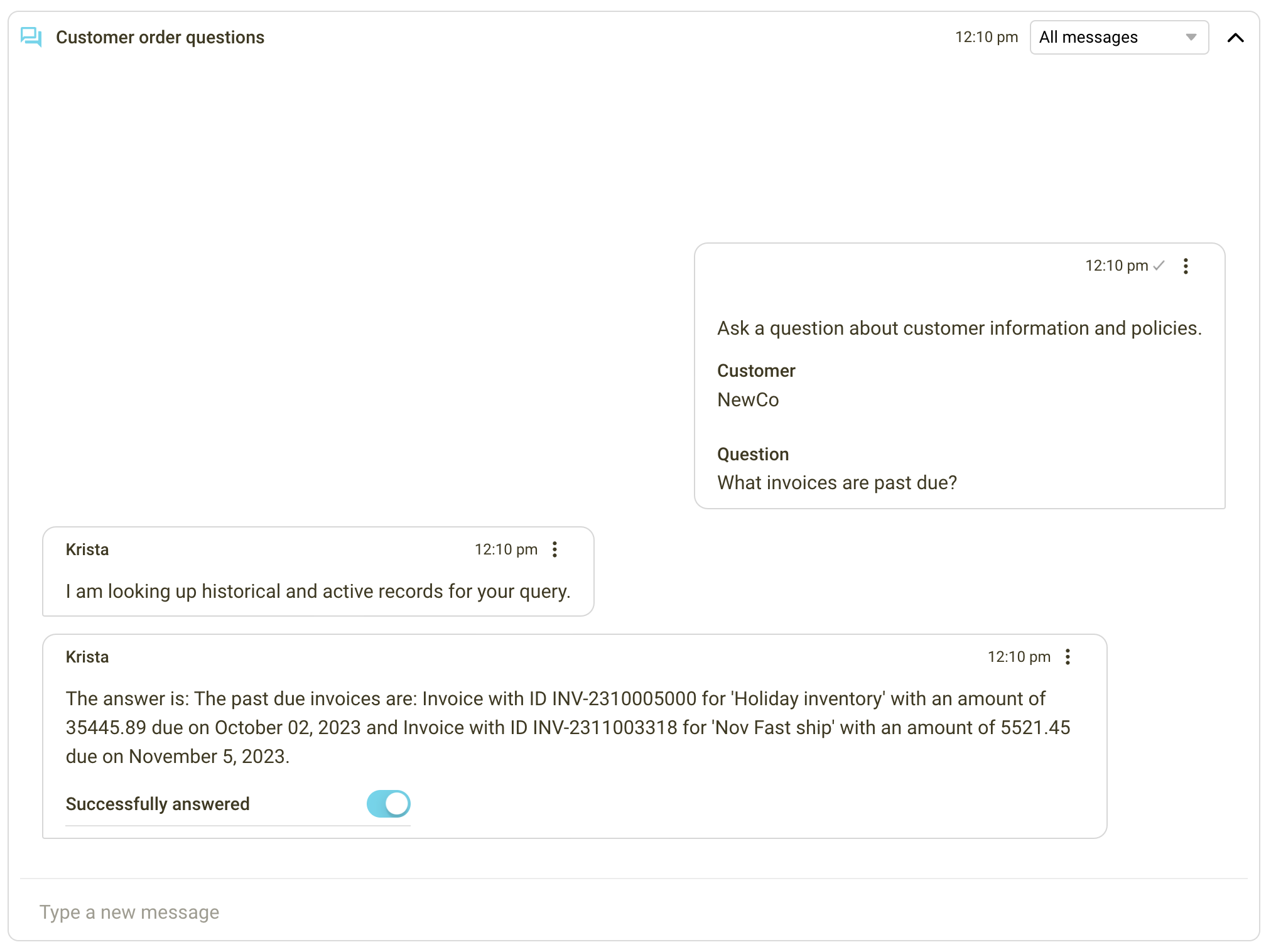
Krista, again, retrieves information from the accounting system and shares, “Past due invoices include: Invoice ID INV-2310005000 for ‘Holiday inventory’ due on October 02, 2023, amounting to $35,445.89, and Invoice ID INV-2311003318 for ‘Nov Fast ship’ due on November 5, 2023, amounting to $5,521.45. This customer owes a total of $40,967.34, exceeding the $25,000 threshold. Therefore, any new orders will be held until past invoices are settled.”
Armed with this information, the agent can now explain to the customer the reason for their orders being on hold. Integrating and automation the workflow across multiple systems with Krista, not only streamlines the agent’s workflow but also uplifts customer satisfaction with prompt, accurate responses. This scenario is a perfect demonstration of AI’s potential to streamline workflows and drive customer service excellence.
But the use case doesn’t end here. This concept also extends to inbound emails from customers, where Krista can either respond directly or assist an agent in crafting a suitable response.
RAG presents several key advantages in customer service applications. First, it enhances factual consistency by minimizing the chances of AI models generating false information. This is achieved by augmenting the generation process with information sourced from reliable databases to produce an accurate answer. This removes large language model fine-tuning needs since answers are generated from your systems and knowledge library. Using an LLM as a tool in the process versus trying to make it the solution allows your processes to be adaptable should one LLM provide better responses or innovate faster than other models. This adaptability enables businesses to interchange models and not be stuck with their original choice. Second, RAG provides traceability for claims, granting users access to the information sources utilized by the AI. This transparency facilitates an understanding of the AI’s reasoning, fostering trust in its abilities.
Embrace the Informed AI Revolution with Krista
Step into a world where the constraints and limitations of AI are vanquished; embrace Krista. Krista redefines the automation landscape from customer interactions and research methodologies to governance risk and compliance. Krista boosts natural language processing, marrying precision and context awareness underneath a secure, trustworthy infrastructure. Imagine a future where AI not only understands but anticipates with an unmatched acumen—this future is now. Don’t let your business lag behind; harness Krista’s RAG capabilities. Are you ready to make your AI not only intelligent but also exceptionally informed? Engage with Krista today and lead your company’s AI journey!








