Scott King
Well, hey everyone, this is Scott King and that is Chris Kraus. Hi Chris, How’s it going?
Chris Kraus
It’s going well.
Scott King
Thanks for listening to this episode of the Union Podcast. Today we’re going talk about how to choose an LLM, and how to choose a large language model. There’s lots of interest in this area. People are trying to figure out if it can work for them if they think it can. Now they need to choose which model is gonna be right for them. It’s not an easy task, Chris. What are some of the people asking us about in terms of either one, will it work? And then, yes, I think it’ll work. How do I figure out which one’s going to be best for my business?
Chris Kraus
Yeah. So we’re seeing two types of buyers. One is we know LLMs will solve our problem. We need to figure out how to bring it into the organization. We need to test multiple of them and we’re worried because customer service knowledge management, and self-service of an HR, that’s a different use case than proprietary stuff in the backends. But the other is people saying, I’ve heard of this, but how do I test it to see if it’ll solve my problem? Can it answer my customer’s emails in a call center? Or, can it answer questions about my product and manuals? So we’re seeing two camps. One is, we know this will work, we gotta figure out which one. The other is trying to figure out if this works for my data since they are earlier in the lifecycle and curious if their business is so different that it won’t work for them.
Scott King
And then there are lots of variables, right? Any kind of IT project has resource constraints, have budgetary constraints. I’ve played with some of the LLMs, and subscribed to a couple of them that I use, but I’m just using it for point stuff, right? In the earlier McKinsey reports that we’ve covered, sales and marketing is like the number one use case because you can use it standalone, but that’s not what we’re talking about, right? We want to use it to help a certain business function like HR, like knowledge management portals and customer service, right?
Chris Kraus
Right, processes with lots of consumers and lots of data. That does change the concept, right? You can have multiple business cases or different use cases inside your organization and each one is going to be a little bit different. So if it’s one person using it, the cost isn’t that big a deal. But maybe you’re putting this on your public website as a chatbot. The cost is a big challenge, because if you have 500 people asking questions a day, the bigger problem may be the performance. You want high performance on your public website, but it can’t be too busy. But, on the other side, say it’s in your customer service organization where you’re optimizing the way humans are interacting and you’re trying to decrease response time for things. But in customer support customer service accuracy is important because if you’re on a recorded call, you want to give the person the right information. Accuracy may be the most important thing to them. If it takes two seconds or five seconds or 10 seconds, they can talk around that, but it has to be super accurate. Other things like if you’re using it in the back office, or if R and D is using it or parts of the organization and talking about your supply chain planning or your internal information security may be the biggest concern. It doesn’t matter how much the performance is. You want to make sure it’s highly secure. This shouldn’t go to a public LLM through a public API. I want this to be say one that I’ve hosted internally or our partners hosted for me. That one is the one that’s in the news the most. People are concerned about putting our intellectual property on the internet. That’s the one people think about the most. But in reality, the other two use cases are just as valid. You want to ask yourself what’s your cost, what’s your accuracy, how performative is it, and security, and those things will skew and change based on your use case within different lines of business itself.
Scott King
So with those examples, you’re talking about these different use cases, one’s public cloud, one’s private cloud, and the different performance for each. That would lead you to believe that you’re not going to use one model to do all this, right? One that’s highly accurate may cost more, and then one could be slow. But, for your website, you can’t have visitors leave your website so that has to be a high performance. I guess maybe accuracy could fall off for the sake of performance and cost because these things are going to get expensive, right? If you have a lot of traffic, they’re going to get expensive to even just operate. If it does get too expensive, you have to be able to switch from one to the other, right? You’re not going to deploy one of these like you do your CRM system or ERP system when you pick one and stick with it because the conversion cost is so high. What’s the conversion cost of switching LLMs?
Chris Kraus
So yeah, what you’re talking about is huge, right? If you spent weeks and months of development to learn how to prompt one, we’ve talked about that in another podcast, how do you prompt an LLM, then you’ve written all the code behind it to connect to it, that’s a huge change. That’s a software development lifecycle. That’s a project plan you have to do. So you wanna be able to swap those very quickly because like you mentioned, this isn’t like an ERP. You’re not just gonna have one. You’re gonna have multiples and they will change over time. What was good today may not be as good in six months because there’s a new open-source model, for example, that came out or a new offering, from Bard, ChatGPT, or Watson. When someone has a new offering, that gives you more accuracy and more performance, you want to swap those.
The other thing is, ideally these will get cheaper every time. For instance, if you have ChatGPT-3.5 versus 4. Ideally, the new one is always more expensive than the previous one. But is it good enough? It is a weighting or balancing act of if the accuracy is good enough and the performance good enough for the cost. You’re not always gonna go for the perfect one. It’s like you’re not gonna always use the most expensive way to ship something. If you want to ship a letter and it has to be there tomorrow by 10, you’re gonna pay a lot for overnighting. But if it’s something to get there in three or four days, you’ll send it in a slower route. So it’s the same type of thing. You have to look at each use case and balance which is going give you the good enough answers, the good enough accuracy, the good enough performance, and they will change. As models increase, different ones come into the market, different ones are removed, and they will change. You may say, today I’m using, say, ChatGPT-3.5, and watsonx comes out with a new one, or Bard comes out with one, and you’re like, okay, this accuracy is much better so I’m gonna need to change because I need the accuracy of the new one, right? So they will change over time, but you don’t want to hard code and have a software development lifecycle to swap them. You want it to be plug-and-play by swapping the interfaces for them.
Scott King
If we’ve learned anything in delivering software, it’s that hard coding just freezes innovation, right? And these things, like they innovate so quickly, you’re going to be frozen in time as somebody else outpaces you.
Chris Kraus
Yeah, the velocity in which you can change these and re-evaluate them is key, right? Because it is early days, and they’re making huge advancements.
Scott King
All right, so how do you choose an LLM? How quickly can you do this? How can you test them? I think we may be the experts in this, right?
Chris Kraus
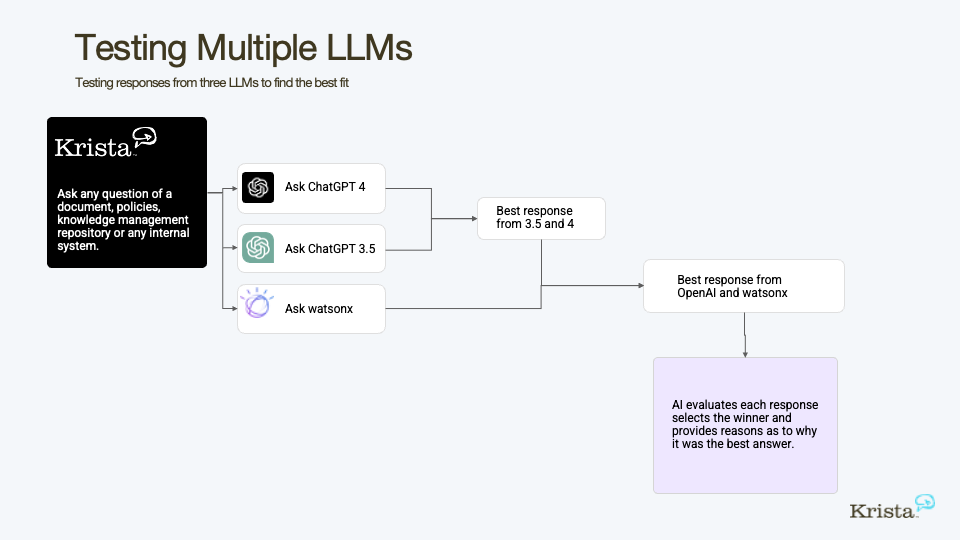
Well, yeah, you may need to test them, right? So if you think about the way we’ve done testing in the past, sometimes it’s software testing, it’s regression testing. So you ask a question, you have a standard response, so you regress over time to do the same. But in sports, we do tournaments, right? So if you think about a testing tournament, you will have two people pair off, they go to the next bracket, and two people pair off the next bracket. So it’s, we wanna create a tournament, if you will, to compare the LLMs to see how their responses are. And when you do that, you can look for accuracy. You could look at response times. You could look at the cost. All those things you can do through a tournament. So think about the same way you would bracket in a tournament. I think there’s a good image right here about that, how it would look like a testing tournament. That’s a great way to do it. People understand that.
Scott King
All of these images are from a paper that we’ve written Comparing Large Language Models for Your Enterprise. It’s a guide on how to do this so you can run LLM test like we did. We ran our tournament against a third-party report that we like because we have used several McKinsey reports in The Union podcast. After all, they’re very well done and they’re very well researched and the visuals are fantastic. In our tournament Chris we tested three LLMs. We tested ChatGPT-3.5, ChatGPT-4, and watsonx. Chris, how was the test set up? Can you explain to people what we did and how they could do that?
Chris Kraus
We took this document, the McKinsey document The State of AI in 2023, Generative AI’s Breakout Year. It was cool because it was actually where people are talking about what they’ve operationalized, what they’ve done. So we gave Krista this document, she read the contents of it, and then we asked her to say, when we give it a question, search this document for the answers, and then give those answers to the LLM and ask them to summarize it. So what we did is we started, say, with ChatGPT first. We said ChatGPT-3.5 versus 4. Given that they have the same answer, can you each summarize them to answer the question we’ve done? And then we use AI to judge that. So normally, judging in something like this you need to have some type of very consistent judging rules, so we ask an AI engine to compare them on accuracy, readability, and that type of stuff. So we actually said, judge this to tell us which one’s better. The trick is we use software to do that. So this happened in machine speed.
Scott King
You’re talking about judging. How did we judge the winner? How does the AI know which one’s better?
Chris Kraus
So what we did is we asked the AI engine, in this case, watsonx, running Google Flan-ul2, is the engine underneath it. We said, based on these facts, who did a better job of summarizing them? And it would give you a comparison. You can see there’s a slide there that says there are the two answers, and it tells you why one was preferred over the other one, whether it was the number of facts that were given or the sentence structure, things like that. So we said, based on this information, who did a better job?
And so we actually ask AI to judge AI’s results. It would take forever for humans to do it, and it might be a little subjective. So it’s gonna do it in a more methodical, consistent way.
Scott King
To have a human read all the answers and judge it would be incredibly inconsistent, right? Because one, we ran so many questions and we did the test so many times, we ran it like 10 times to look at if there were any variability in the results, and you can see here there’s a little bit of variability of all the questions we asked. So all the visuals that we have, are just one of the questions that we asked. Like, what is the most important objective using AI? So then we had everybody answer that, generate answers, and then judge it. It turns out, you know, Watson was the best in this instance, but that was only one of 100 instances, right? So we had 10 questions that ran it 10 times. But it was interesting that the results were fairly consistent. Like, Watson answered better based on this test, 42 times, ChatGPT-4 42 times, and then ChatGPT-3.5 16 times. That’s just one use case, right? We talked about other use cases earlier with customer service, and agent assist, you would have to do this multiple times, and hard coding this would be a very timely exercise, and I don’t think people have that kind of time.
Chris Kraus
Oh yeah, it would take an army of engineers, an army of data scientists, and months to do. And if we walk backwards to the use cases, if you think about FAQ answers and a public-facing chatbot, you’re actually looking for reading documents and summarizing things in paragraphs of data.
If it’s in customer service, you may dynamically give the model, here’s the customer’s invoices, this is our POs, this is the status of their shipments, and give it a lot of like tables of data, and then want it to infer things from the tables of data. Based on your use case, the type of questions and the source of information is going to be different. So you’re going to want to test them to see which model does better on which type of answer. Is it because it’s drawing conclusion, or is it summarizing information in paragraphs? And we saw that. You were smart. When we looked, that’s when we’re like, wow, it’s kind of inconsistent. And then you turn the graph sideways, which quite honestly, I wrote this conversation in Krista very quickly, probably in 20 minutes. Scott ran it 10 times so that took him an hour and then it probably took him more time to build the charts in PowerPoint to summarize it.
Scott King
I guarantee you it took me longer to create the PowerPoint than to run the test.
Chris Kraus
So, literally, we’re talking 20 minutes of me authoring this in Krista, an hour of running it 10 times with 10 questions and that was the long pole. What’s interesting, if you look at the results by question bar chart, you’ll see the third, fourth, and fifth. Watson X did a better job of answering those, but it was summarizing data inside of a table. So that tells you if your use case is to get tables of data summarize them and draw conclusions, that LLM is better suited. Where other ones, where it was like summarizing paragraphs or data inside of paragraphs, ChatGPT-4 did a better job. It had a better sentence structure in that. So you will, like we mentioned before, you’ll want multiple of these. And it’s partially when we talk about the accuracy, it’s like because some models do better at answering different types of questions. Some will be more performant, but they have different costs. But this was really interesting because if you read the article and you look at the results, you’ll figure out that some of these are summarization based, some of these were drawing conclusions based, some things were stack ranking.
Scott came up with the questions and the point was to give us questions that had different types of summary information. So you guys could see that, hey, you can do this. This is literally hours of work. This is not an army of data scientists, engineers and six months of that. We would say this is actually operationalized and production-ready.
If a customer said, OK, here’s my document. Here’s a Word document. Or here are five Word documents. And there are two Excel spreadsheets of my data. We could put this in Krista in a matter of four or five minutes, because the conversation says, give me a zip file. And then they could come up with 10 questions to ask. And we could ask those questions and get the results. This is something. This is an hour’s work. This is not months of data scientists and development.
Scott King
I think that’s where people are, right? Because just the lack of understanding of what tools are available to run a test like this, because like Chris said, it was fairly simple. And we have all of the data in a Google Doc that you can read like all of, all 100 responses and the reasons why each model one, you know, one test version over another. It’s really, really interesting to read the reasons. I think the reasons are the most interesting part for me. But this is simple to do. If you do want to do a test like this, just contact us on the website at Krista.ai, right? And then we’ll actually either show you how to perform the tests or perform the tests for you based on whatever document you want. Chris mentioned a couple of Word documents. This could be like your employee handbook or, something that’s simple that you have on hand is gonna be easy to do. And then it’ll give you an idea of how easy and simple this really is.
Chris Kraus
Yeah, and yeah, it would answer those two questions we started with, like, will this work for my stuff? Or it’ll work, which LLM will work the best, right? So it’ll answer those two questions we started our conversation with.
Scott King
So Chris, to close it out, we talked about the different use cases. You’re gonna have to look at different requirements for cost, accuracy, performance and data security is really important because people want to interrogate and ask questions of proprietary data. It’s either in a document or a system, right? So we didn’t really talk about systems. We’re mostly talking about documents because we’re trying to simplify this explanation. But just like if somebody is going to do this, what are the steps that they need to take? What are the two, three, and four steps from this point forward? What do they need to do?
Chris Kraus
If so if you want to be very low risk, take something that is publicly available, maybe it’s FAQs on your website, it’s recalls, it’s information you may have on your website. We’ll take the Word documents of that, that’s source information, read it into Krista and start answering questions. That way you don’t have to worry about proprietary information. Now maybe, and that’s great for that first use case. If you’re in the second use case where you know we want to do this, we just need to start comparing them, and you’ve hosted a Hugging Face or an LLM inside your organization, if we have API access to that, we can compare it to multiples, say something in Watson and yours and another one, and compare your homegrown or your home trained models to the other ones. And that was just an exercise of we would need access to it via the APIs, but that’s something that can be done there. So I think everybody can probably find something to say, okay, how does this work to get the concept of continuously testing this every time with stuff they have on their public website and we consume it and read it. Then, when people are sold on it, we can compare very specific models. That’s just a little bit of work and we can wire them up. But that’s not months, that’s not weeks, that’s a couple days of work to wire those up to get the answers and then run these tests itself.
Scott King
Alright, that’s fantastic. So thanks Chris, and thanks for working with me on this project and helping me run my test for this report, so I appreciate it. You know, one, please do read the report. Two, take a look at the data. And then three, contact us so we can help you run your own test. Thanks Chris, and until next time.