
Natural Language Processing (NLP) or Natural Language Understanding (NLU) is a subset of Artificial Intelligence (AI). There are many benefits when using the technology, and I am surprised at the pushback from technical people when talking about deploying it. I guess there is a difference between learning about a technology in academia and the complexity of actually deploying it.
So how do we get past all the pushback when chatbots having conversations, intelligent automation promises to be better than old-school EAI and SOA?
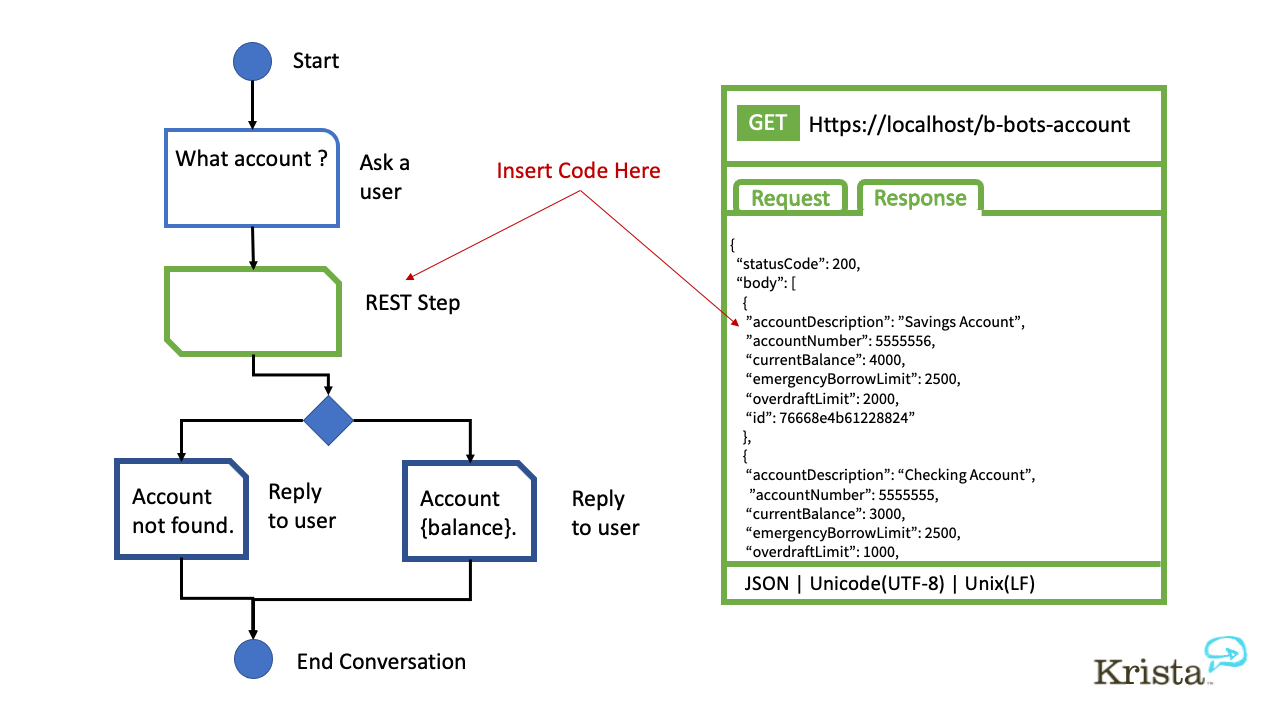
One problem is the hype and over-promises of how easy it is to build chatbots with low code platforms and GUI tools. For example, there are many examples on YouTube displaying how to develop conversations or chats using pretty graphical examples. They look easy. But, when you want more interesting or complex steps like getting data from systems via REST or SOAP, you end up with a “paste code here” or “parse the JSON response here” part of the UI. It’s far beyond easy.
Another common over-promise is that it is easy to build the conversation and responses. In some cases, you build a simple decision matrix via the UI. After a while, you find out all of the variables in the conversation have created a mess. The other option is to create a machine learning (ML) model to look at data and provide observations and predictions. You might as well pull out your calculus textbooks and remember how all of this complex math works to build a ML algorithm. Building the ML is a specialized discipline in applied mathematics. Just because you can take a distant learning course does not mean you have the mathematics to build them. When asking a mathematician how long it will take to observe, hypothesize, and build an algorithm to try, they will tell you it takes time. And, the time is never measured in days or weeks. Hopefully, it is measured in quarters. Let’s say it is not new math for mere mortals.
In academia, you can download sample data from many sources. Google for them, and you’ll find thousands of examples available. Typically, the examples you find have already been obfuscated and anonymized, don’t share any personal information, are specific to a subject or topic area, and clear of satire and profanity. However, I just described the problem. How do you start on the company’s greatest intelligent automation effort front-ended by NLP when you don’t already have all of the right questions with the correct answers to use in NLP training? Instead, one needs to bring up a non-helpful chatbot on a website to gather example questions and reinforce that they never get the correct answer from them?
How Much Data is Enough to Train AI?
If the theory is the more observations, the smarter AI gets; how do you know you have enough data? How many observations are enough for your intelligent automation processes to project intelligence? John Michelsen stated years ago that to move past false positives when training the algorithms or to move from 80% accuracy to the upper 90th percentile takes time. In a mobile cybersecurity platform, 8TB of data was not enough. Getting to 12TB did not increase accuracy, but 15TB of data was the magic number. Training the ML with 15TB of data was enough to train and prevent false positives.
 Messy data is a huge problem. In her blog AI Weirdness, Janelle Shane points out how AI gets the wrong idea when identifying important aspects of an image—for example, asking AI for the most important parts of an image for recognizing a fish. It turns out the fingers of the person holding the fish were the most important part of the image. (sound of hand slapping forehead here).
Messy data is a huge problem. In her blog AI Weirdness, Janelle Shane points out how AI gets the wrong idea when identifying important aspects of an image—for example, asking AI for the most important parts of an image for recognizing a fish. It turns out the fingers of the person holding the fish were the most important part of the image. (sound of hand slapping forehead here).
Which Comes First?
Now, back to the pushback. I have encountered the proverbial, which comes first, the chicken or egg. This is similar to NLP understanding what I am asking for or providing 200,000 examples of questions supposed to be answered. Having a degree in statistics tells me there must be a better, more deterministic way to solve the problem when companies start on new intelligent automation efforts and want to make the easily consumed via NLP.
These efforts always start with an IT proof of concept. After the proof, the finding is presented based on what IT specialists find. Unfortunately, that usually ends up starting on the wrong foot. It would help if you had input from both subject matter experts (SME) and novice users to validate your findings. Several representatives from both groups together who represent the actual customers of the intelligent automation efforts start you off on the right foot. The actual users who will be using the NLP every day to accomplish their jobs are in a great position to help give you examples to achieve all of the necessary building blocks for your NLP.
How to Train Your NLP Engines
- Group your conversations into topics
- Include discussions from novices and experts in each business area
- Inclusion of different roles in the organization
Grouping topic conversations is a listening exercise
Creating a specific list of topics vs. inferring them from terabytes of data provides you the same lift academia gets with sample data for learning for topic modeling. Think of it this way; context is everything. This is true when two people are speaking or you are organizing your NLP conversations. For example, get account information for NewCo does not have much context. Is the account information for accounts payable or accounts receivable in the accounting department? Or new opportunity or verifying a customer name for support in the CRM?
Create a list of your topics based on the questions’ subject across multiple roles in an organization. Organize topics based on question subject matter, not by organizational boundaries. Leaving this up to a bit of luck means you could end up with the same subject but split into different views.
Include conversations from SME to novice in a business area
A natural occurrence when you become an expert is you end up with shorter terms and acronyms to make communications faster. A salesperson would think of products by codes or short names, but a support rep may only know the formal names of products. When a question comes along about the warranty period for my “3800-watt generator” or “dual fuel 3800” in a support chat and sales asks what is the warranty for GSLP3800, they are talking about the same item. These variances can have a specific effect on how your keyword extraction and named entity recognition works. Getting examples from different experience levels allows you to realize you need to look items up by name, short description, or model number.
Inclusion of different roles in the organization to expand vocabulary
Topic classification and intent detection require the business to provide questions to be answered with different information. When creating your example conversation questions, you will end up grouping by topic. Once grouped by topic, different synonyms will show up. For instance, I have worked at companies that have a deal desk to review sales opportunities. Heads of sales are constantly asked about the status of an opportunity. Based on your role in the organization, sales support, or salesperson, you would say opportunity vs. deal. Both are correct and easily solved by specifying that a synonym of an opportunity is a deal. “What is the status of the deal at NewCo” and “give me opportunity status for NewCo” should both be the same NLP conversation returning the status data from the CRM. Trying to gather tens of thousands of examples to create the training data for AI could take 100 years based on sales volume.
When approaching your next greatest intelligent automation project and looking to the front end with NLP or NLU, don’t get stuck. For cool new disruptive processes, you won’t necessarily have a long history of questions and answers to mine for traditional NLP training. Instead, you can listen to conversations with your business and build out your NLP vocabulary and start from there.
Newer NLP platforms allow you to specify topics and identify how sentences are segmented, words are tokenized, and common stop words. This means you can build NLP for questions not yet asked or if they have, and no one previously documented them to collect them electrically for processing later. Companies are creating domain specific language (DSL) to describe the necessary input for the NLP engine to start working and working well. The next step is to get the 1st TB of data for the mathematicians to begin building the ML theory, and training is just the start of learning to get predictions.
With Krista you don’t have to sit and wait to build you next greatest intelligent automation project that includes NLP because you don’t have terabytes of data to train classic models. We allow you to organize topics and conversations and then via heuristics and automation train the NLP engine to identify conversations, determine context of data and provide better user experience. When decisions need to be made or assisted, we constantly learn from conversational outcomes and include them in our AI models so they are continuously learning.






